Compacting 지옥에서 벗어나다
그 답답한 Compacting
Claude Code를 좀 오래 써온 사람이라면 다들 공감할 거다.
작업하다 보면 슬슬 뜨는 그 메시지. “Compacting conversation…” 이게 뜨는 순간 마음이 조마조마해진다. 대화 내용이 압축되면서 앞에서 했던 맥락이 날아가거든.
특히 PDF를 많이 읽어야 하는 작업이 문제였다. 어마어마하게 긴 문서를 읽히다 보면 3~4번 압축이 일어나고, 잘못하면 그냥 오류 나서 뻗어버리는 경우도 있었다. 그래서 항상 “지금 이걸 보내면 Compacting 뜨겠지…” 하면서 살짝 계산하면서 써야 했다.
이게 은근히 스트레스다. AI한테 작업을 시키는 건데 오히려 내가 AI의 컨텍스트 용량을 관리해주고 있는 셈이니까.
어느 날 Switch Model을 눌러봤더니
오늘도 한번에 읽어야 하는 PDF가 너무 많았다. 평소처럼 버벅거리기 시작해서 “아 또 시작이구나” 싶었는데, 문득 Switch Model을 클릭해봤다.
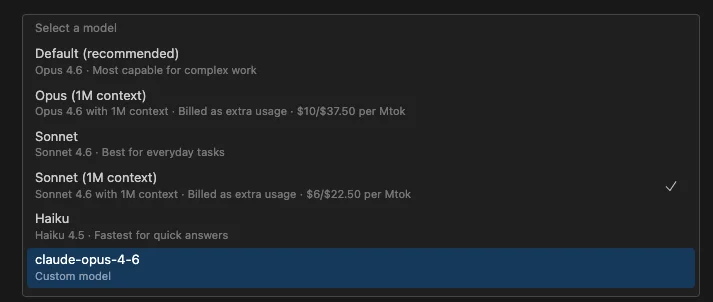
어라? 모델별로 1M context 옵션이 추가되어 있네?
얼마 전까지만 해도 Claude Code에 정식으로 없었던 것 같은데. Opus (1M context), Sonnet (1M context) 이렇게 따로 선택할 수 있게 되어 있었다.
바꿔봤더니 세상이 달라졌다
일단 바꾸고 나서 첫 인상. “뭐야 이게?”
기존에는 읽다가 중간에 압축하고, 또 읽고 압축하고, 그러다가 맥락이 꼬여서 엉뚱한 결과가 나오고… 이런 일이 반복이었다. 근데 1M context로 바꾸니까 어마어마하게 많은 양의 PDF도 한번에 쭉 읽어서 처리해버린다.
Compacting이 뜰까 눈치 보면서 쓰던 그 답답함이 싹 사라졌다.
진짜 체감이 확 다르다. 같은 도구인데 컨텍스트 윈도우 하나 차이로 이렇게 달라지는구나 싶었다.
근데 공짜는 아니다
당연히 좋은 건 돈이 든다 ㅎㅎ
1M context 모델은 extra usage로 추가 비용이 발생한다. 스크린샷을 보면 Opus (1M context)는 $10/$37.50 per Mtok, Sonnet (1M context)는 $6/$22.50 per Mtok으로 표시되어 있다.
AI 구독 비용에 대한 생각은 예전에도 썼었는데, 돈을 지불하더라도 가끔 스위칭해서 사용할 만한 가치는 충분하다고 느꼈다. 매일 1M으로 쓸 필요는 없고, PDF를 대량으로 처리해야 할 때만 잠깐 바꾸면 된다.
Claude는 왜 비싸도 계속 쓰게 되는가
Claude Code를 오랜 기간 써오면서 느낀 게 하나 있다.
항상 다른 AI보다 20% 정도 비싸게 책정된다. 용량도 좀 짜다. Opencode 같은 오픈소스 대안도 나오고, Cursor도 써봤고, 여러 도구를 비교해봤다.
근데 결국 Claude Code로 돌아오게 된다.
이유는 단순하다. 확실한 성능을 보장한다는 거다. 비싼 만큼 결과물이 다르다. 코드 이해력, 맥락 파악 능력, 에이전트 모드의 완성도… 이런 부분에서 아직까지는 Claude가 한 수 위라고 느낀다.
이게 Claude를 계속 사용하게 하는 원동력인 것 같다.
1M이 기본이 되는 날이 오겠지
향후 AI가 더 발전해서 1M context가 기본 모델이 되면… 작업이 진짜 많이 편해질 거다. 지금은 extra usage로 추가 비용을 내야 하지만, 몇 년 지나면 200K가 그랬던 것처럼 1M도 당연한 게 되겠지.
그때가 되면 Compacting 걱정 없이 프로젝트 전체를 한 번에 넘기고, 수백 페이지 문서도 한 방에 처리하고… 상상만 해도 좋다 ㄷㄷ
아무튼, 지금 당장 대용량 작업이 필요한 분들은 Switch Model에서 1M context 옵션 한번 써보시라. 비용이 좀 들지만 Compacting 지옥에서 벗어나는 해방감은 값을 매기기 어렵다.
Agent Teams까지 합치면?
그리고 하나 더. 얼마 전 Claude Code에 Agent Teams 기능이 나왔다. 여러 개의 에이전트를 동시에 띄워서 각자 독립적으로 작업하고, 서로 소통까지 하는 기능이다.
이거랑 1M context를 조합하면 어떨까 생각해봤다.
무거운 작업, 예를 들어 수백 페이지 문서를 분석하거나 프로젝트 전체를 파악해야 하는 에이전트에는 1M context 모델을 붙이고, 간단한 파일 수정이나 테스트 실행 같은 가벼운 작업에는 Haiku 같은 빠른 모델을 붙이는 거다. 무거운 놈은 무겁게, 가벼운 놈은 가볍게. 작업 성격에 따라 모델을 분배하는 방식.
아직은 Agent Teams 자체가 실험 기능이라 이런 조합을 완벽하게 세팅하기는 어렵지만, 방향성은 확실히 이쪽인 것 같다. AI가 혼자 일하는 시대에서 AI가 팀으로 일하는 시대로 넘어가고 있는 거니까.
1M context + Agent Teams가 기본이 되는 날이 오면, 진짜 개발 생산성이 지금과는 차원이 다를 것 같다 ㄷㄷ