Escaping Compacting Hell
The Dreaded Compacting
If you’ve been using Claude Code for a while, you know exactly what I’m talking about.
You’re deep into a task, and then that message appears: “Compacting conversation…” The moment it pops up, your heart sinks. The conversation gets compressed, and the context from earlier just vanishes.
PDF-heavy tasks were the worst. Feed it a massive document and you’d get 3-4 rounds of compression. Sometimes it would just crash with an error. So I was always doing mental math: “If I send this now, compacting will probably kick in…” It was a constant calculation.
The irony wasn’t lost on me. I’m supposed to be delegating work to AI, but instead I’m managing its context window capacity.
Then I Clicked Switch Model
Today I had too many PDFs to process at once. Things started lagging as usual, and I thought, “Here we go again.” On a whim, I clicked Switch Model.
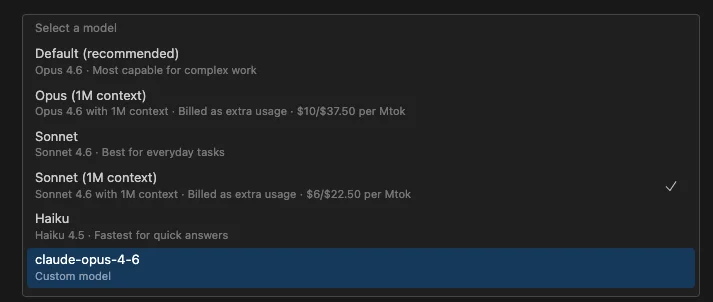
Wait — 1M context options had been added for each model?
I could’ve sworn these weren’t there before. Opus (1M context), Sonnet (1M context) — each available as a separate selection.
Everything Changed
My first impression after switching: “What is this?”
Before, it was read-compress-read-compress, with context getting tangled and producing garbage results. With 1M context, it just plowed through massive volumes of PDFs in one shot.
The constant anxiety of watching for compacting? Gone.
The difference is night and day. Same tool, but the context window alone makes it a completely different experience.
Nothing Good Is Free
Of course, better comes at a price.
The 1M context models are billed as extra usage. Looking at the screenshot: Opus (1M context) runs $10/$37.50 per Mtok, and Sonnet (1M context) is $6/$22.50 per Mtok.
I’ve written about AI subscription costs before, and even with the extra charges, it’s worth switching occasionally. You don’t need 1M every day — just flip to it when you have a heavy batch of documents to process.
Why I Keep Paying for Claude Despite the Price
One thing I’ve noticed after using Claude Code for a long time:
It’s always priced about 20% higher than the competition. The capacity feels a bit stingy too. I’ve tried open-source alternatives like Opencode, experimented with Cursor, and compared plenty of tools.
But I keep coming back to Claude Code.
The reason is simple: it delivers consistent, reliable performance. You get what you pay for. Code comprehension, context understanding, the quality of agentic mode — Claude is still a cut above in these areas.
That’s what keeps me coming back.
1M Will Be Standard Someday
As AI continues to advance, 1M context will eventually become the default. Right now we pay extra for it, but in a few years it’ll be as standard as 200K is today.
When that happens — feeding an entire project in one go, processing hundreds of pages without breaking a sweat — just thinking about it gets me excited.
For now, if you need to handle large-scale tasks, give the 1M context option a try in Switch Model. It costs extra, but the relief of escaping compacting hell is hard to put a price on.
What About Agent Teams?
One more thing. Claude Code recently launched Agent Teams — a feature that lets you spin up multiple agents working independently and communicating with each other.
I started thinking about combining this with 1M context.
Imagine assigning a 1M context model to agents handling heavy lifting — analyzing hundreds of pages or understanding an entire project — while giving lighter agents running simple file edits or test execution a fast model like Haiku. Heavy tasks get the heavy model, light tasks get the fast one. Distributing models based on the nature of the work.
Agent Teams is still experimental, so this kind of setup isn’t fully possible yet. But the direction is clear. We’re moving from AI working solo to AI working as a team.
When 1M context + Agent Teams becomes the norm, development productivity will be on an entirely different level.